
利用tess-two和cv4j实现简单的ocr功能
ocr
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
Tesseract
Tesseract是Ray Smith于1985到1995年间在惠普布里斯托实验室开发的一个OCR引擎,曾经在1995 UNLV精确度测试中名列前茅。但1996年后基本停止了开发。2006年,Google邀请Smith加盟,重启该项目。目前项目的许可证是Apache 2.0。该项目目前支持Windows、Linux和Mac OS等主流平台。但作为一个引擎,它只提供命令行工具。 现阶段的Tesseract由Google负责维护,是最好的开源OCR Engine之一,并且支持中文。
tess-two是Tesseract在Android平台上的移植。
下载tess-two:
compile 'com.rmtheis:tess-two:8.0.0'
然后将训练好的eng.traineddata放入android项目的assets文件夹中,就可以识别英文了。
1. 简单地识别英文
初始化tess-two,加载训练好的tessdata
private void prepareTesseract() {
try {
prepareDirectory(DATA_PATH + TESSDATA);
} catch (Exception e) {
e.printStackTrace();
}
copyTessDataFiles(TESSDATA);
}
/**
* Prepare directory on external storage
*
* @param path
* @throws Exception
*/
private void prepareDirectory(String path) {
File dir = new File(path);
if (!dir.exists()) {
if (!dir.mkdirs()) {
Log.e(TAG, "ERROR: Creation of directory " + path + " failed, check does Android Manifest have permission to write to external storage.");
}
} else {
Log.i(TAG, "Created directory " + path);
}
}
/**
* Copy tessdata files (located on assets/tessdata) to destination directory
*
* @param path - name of directory with .traineddata files
*/
private void copyTessDataFiles(String path) {
try {
String fileList[] = getAssets().list(path);
for (String fileName : fileList) {
// open file within the assets folder
// if it is not already there copy it to the sdcard
String pathToDataFile = DATA_PATH + path + "/" + fileName;
if (!(new File(pathToDataFile)).exists()) {
InputStream in = getAssets().open(path + "/" + fileName);
OutputStream out = new FileOutputStream(pathToDataFile);
// Transfer bytes from in to out
byte[] buf = new byte[1024];
int len;
while ((len = in.read(buf)) > 0) {
out.write(buf, 0, len);
}
in.close();
out.close();
Log.d(TAG, "Copied " + fileName + "to tessdata");
}
}
} catch (IOException e) {
Log.e(TAG, "Unable to copy files to tessdata " + e.toString());
}
}
 拍完照后,调用startOCR方法。
拍完照后,调用startOCR方法。 private void startOCR(Uri imgUri) {
try {
BitmapFactory.Options options = new BitmapFactory.Options();
options.inSampleSize = 4; // 1 - means max size. 4 - means maxsize/4 size. Don't use value <4, because you need more memory in the heap to store your data.
Bitmap bitmap = BitmapFactory.decodeFile(imgUri.getPath(), options);
String result = extractText(bitmap);
resultView.setText(result);
} catch (Exception e) {
Log.e(TAG, e.getMessage());
}
}
extractText()会调用tess-two的api来实现ocr文字识别。
private String extractText(Bitmap bitmap) {
try {
tessBaseApi = new TessBaseAPI();
} catch (Exception e) {
Log.e(TAG, e.getMessage());
if (tessBaseApi == null) {
Log.e(TAG, "TessBaseAPI is null. TessFactory not returning tess object.");
}
}
tessBaseApi.init(DATA_PATH, lang);
tessBaseApi.setImage(bitmap);
String extractedText = "empty result";
try {
extractedText = tessBaseApi.getUTF8Text();
} catch (Exception e) {
Log.e(TAG, "Error in recognizing text.");
}
tessBaseApi.end();
return extractedText;
}
最后,显示识别的效果,此时的效果还算可以。
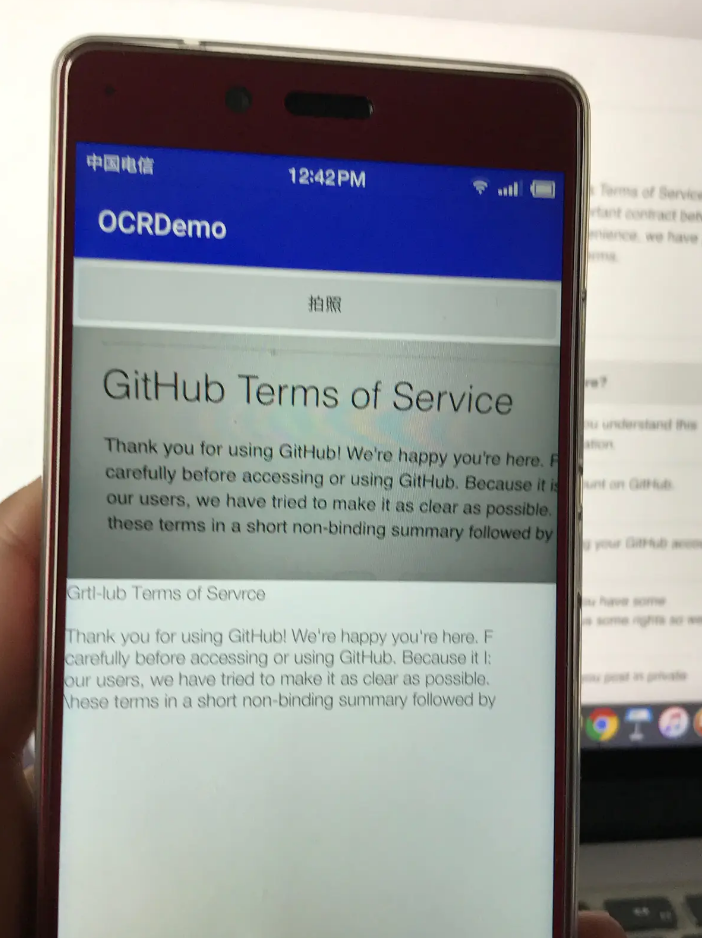 2. 识别代码
2. 识别代码接下来,尝试用上面的程序识别一段代码。
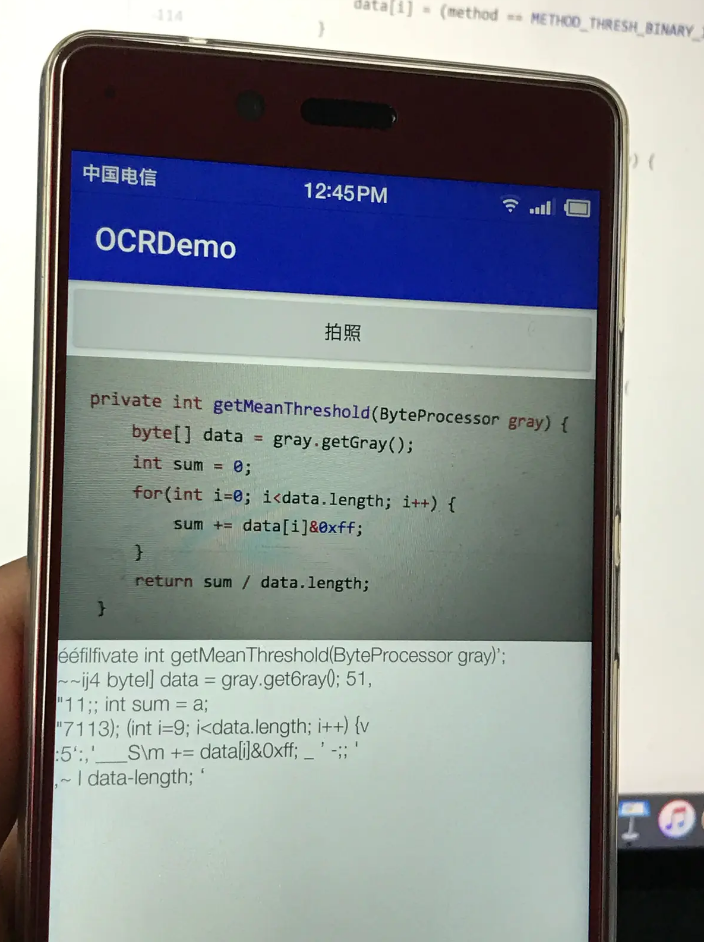 此时,效果一塌糊涂。我们重构一下startOCR(),增加局部的二值化处理。
此时,效果一塌糊涂。我们重构一下startOCR(),增加局部的二值化处理。 private void startOCR(Uri imgUri) {
try {
BitmapFactory.Options options = new BitmapFactory.Options();
options.inSampleSize = 4; // 1 - means max size. 4 - means maxsize/4 size. Don't use value <4, because you need more memory in the heap to store your data.
Bitmap bitmap = BitmapFactory.decodeFile(imgUri.getPath(), options);
CV4JImage cv4JImage = new CV4JImage(bitmap);
Threshold threshold = new Threshold();
threshold.adaptiveThresh((ByteProcessor)(cv4JImage.convert2Gray().getProcessor()), Threshold.ADAPTIVE_C_MEANS_THRESH, 12, 30, Threshold.METHOD_THRESH_BINARY);
Bitmap newBitmap = cv4JImage.getProcessor().getImage().toBitmap(Bitmap.Config.ARGB_8888);
ivImage2.setImageBitmap(newBitmap);
String result = extractText(newBitmap);
resultView.setText(result);
} catch (Exception e) {
Log.e(TAG, e.getMessage());
}
}
在这里,使用cv4j来实现图像的二值化处理。
CV4JImage cv4JImage = new CV4JImage(bitmap);
Threshold threshold = new Threshold();
threshold.adaptiveThresh((ByteProcessor)(cv4JImage.convert2Gray().getProcessor()), Threshold.ADAPTIVE_C_MEANS_THRESH, 12, 30, Threshold.METHOD_THRESH_BINARY);
Bitmap newBitmap = cv4JImage.getProcessor().getImage().toBitmap(Bitmap.Config.ARGB_8888);
图像二值化就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果。图像的二值化有利于图像的进一步处理,使图像变得简单,而且数据量减小,能凸显出感兴趣的目标的轮廓。
cv4j的github地址:https://github.com/imageprocessor/cv4j
cv4j 是gloomyfish和我一起开发的图像处理库,纯java实现。
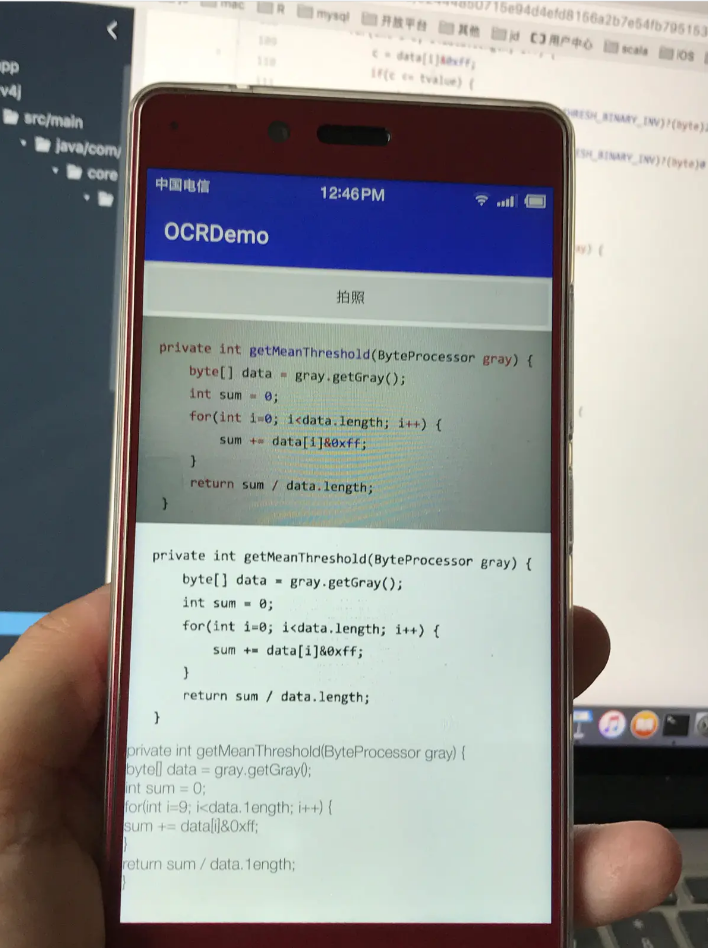
再来试试效果,图片中间部分是二值化后的效果,此时基本能识别出代码的内容。
 3. 识别中文
3. 识别中文如果要识别中文字体,需要使用中文的数据包。可以去下面的网站上下载。
https://github.com/tesseract-ocr/tessdata
跟中文相关的数据包有chi_sim.traineddata、chi_tra.traineddata,它们分别表示是简体中文和繁体中文。
tessBaseApi.init(DATA_PATH, lang);
前面的例子都是识别英文的,所以原先的lang值为"eng",现在要识别简体中文的话需要将其值改为"chi_sim"。
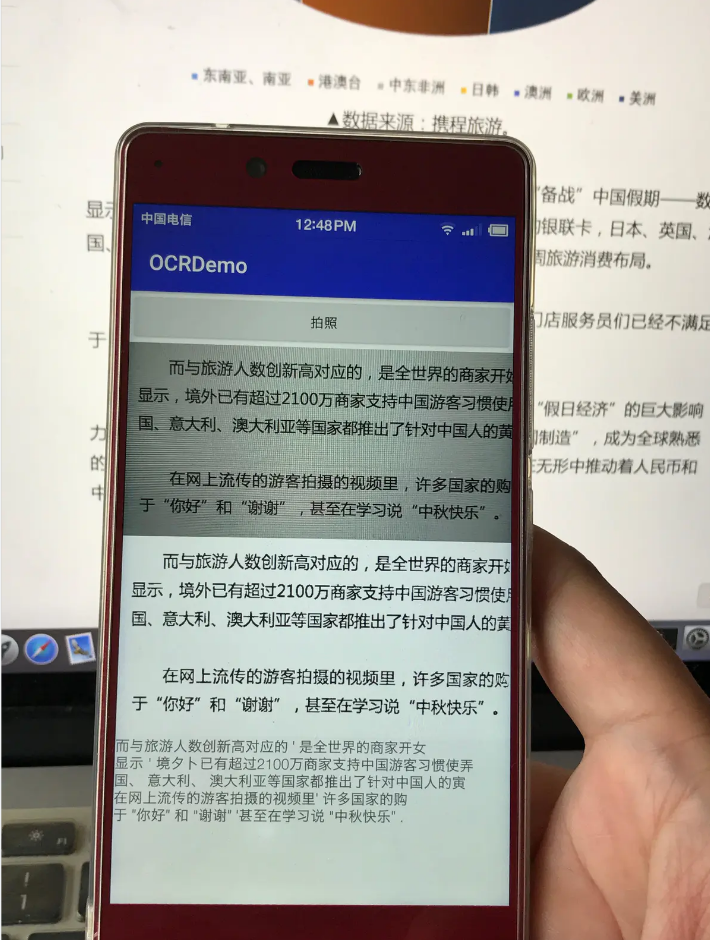 最后
最后本项目只是demo级别的演示,离生产环境的使用还差的很远。
本项目的github地址:https://github.com/fengzhizi715/Tess-TwoDemo
为何说只是demo级别呢?
- 数据包很大,特别是中文的大概有50多M,放在移动端的肯定不合适。一般正确的做法,都是放在云端。
- 识别文字很慢,特别是中文,工程上还有很多优化的空间。
- 做ocr之前需要做很多预处理的工作,在本例子中只用了二值化,其实还有很多预处理的步骤比如倾斜校正、字符切割等等。
- 为了提高tess-two的识别率,可以自己训练数据集。
作者:fengzhizi715
链接:https://www.jianshu.com/p/5314f63c75d8
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
