
java设计模式:中介者模式
前言
在现实生活中,常常会出现好多对象之间存在复杂的交互关系,这种交互关系常常是“网状结构”,它要求每个对象都必须知道它需要交互的对象。例如,每个人必须记住他(她)所有朋友的电话;而且,朋友中如果有人的电话修改了,他(她)必须让其他所有的朋友一起修改,这叫作“牵一发而动全身”,非常复杂。
如果把这种“网状结构”改为“星形结构”的话,将大大降低它们之间的“耦合性”,这时只要找一个“中介者”就可以了。如前面所说的“每个人必须记住所有朋友电话”的问题,只要在网上建立一个每个朋友都可以访问的“通信录”就解决了。这样的例子还有很多,例如,你刚刚参加工作想租房,可以找“房屋中介”;或者,自己刚刚到一个陌生城市找工作,可以找“人才交流中心”帮忙。
在软件的开发过程中,这样的例子也很多,例如,在 MVC 框架中,控制器(C)就是模型(M)和视图(V)的中介者;还有大家常用的 QQ 聊天程序的“中介者”是 QQ 服务器。所有这些,都可以采用“中介者模式”来实现,它将大大降低对象之间的耦合性,提高系统的灵活性。
模式的定义与特点
定义
定义一个中介对象来封装一系列对象之间的交互,使原有对象之间的耦合松散,且可以独立地改变它们之间的交互。中介者模式又叫调停模式,它是迪米特法则的典型应用。
优点
类之间各司其职,符合迪米特法则。
降低了对象之间的耦合性,使得对象易于独立地被复用。
将对象间的一对多关联转变为一对一的关联,提高系统的灵活性,使得系统易于维护和扩展。
缺点
中介者模式将原本多个对象直接的相互依赖变成了中介者和多个同事类的依赖关系。当同事类越多时,中介者就会越臃肿,变得复杂且难以维护。
模式的结构与实现
中介者模式实现的关键是找出“中介者”,下面对它的结构和实现进行分析。
结构
抽象中介者(Mediator)角色:它是中介者的接口,提供了同事对象注册与转发同事对象信息的抽象方法。
具体中介者(Concrete Mediator)角色:实现中介者接口,定义一个 List 来管理同事对象,协调各个同事角色之间的交互关系,因此它依赖于同事角色。
抽象同事类(Colleague)角色:定义同事类的接口,保存中介者对象,提供同事对象交互的抽象方法,实现所有相互影响的同事类的公共功能。
具体同事类(Concrete Colleague)角色:是抽象同事类的实现者,当需要与其他同事对象交互时,由中介者对象负责后续的交互。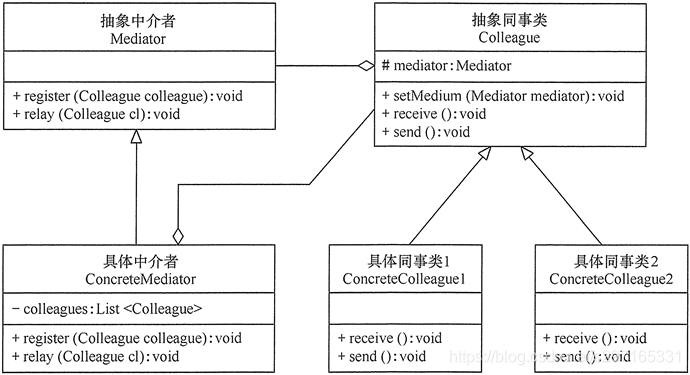
实现
中介者模式的实现代码如下:
package net.biancheng.c.mediator;
import java.util.*;
public class MediatorPattern {
public static void main(String[] args) {
Mediator md = new ConcreteMediator();
Colleague c1, c2;
c1 = new ConcreteColleague1();
c2 = new ConcreteColleague2();
md.register(c1);
md.register(c2);
c1.send();
System.out.println("-------------");
c2.send();
}
}
//抽象中介者
abstract class Mediator {
public abstract void register(Colleague colleague);
public abstract void relay(Colleague cl); //转发
}
//具体中介者
class ConcreteMediator extends Mediator {
private List<Colleague> colleagues = new ArrayList<Colleague>();
public void register(Colleague colleague) {
if (!colleagues.contains(colleague)) {
colleagues.add(colleague);
colleague.setMedium(this);
}
}
public void relay(Colleague cl) {
for (Colleague ob : colleagues) {
if (!ob.equals(cl)) {
((Colleague) ob).receive();
}
}
}
}
//抽象同事类
abstract class Colleague {
protected Mediator mediator;
public void setMedium(Mediator mediator) {
this.mediator = mediator;
}
public abstract void receive();
public abstract void send();
}
//具体同事类
class ConcreteColleague1 extends Colleague {
public void receive() {
System.out.println("具体同事类1收到请求。");
}
public void send() {
System.out.println("具体同事类1发出请求。");
mediator.relay(this); //请中介者转发
}
}
//具体同事类
class ConcreteColleague2 extends Colleague {
public void receive() {
System.out.println("具体同事类2收到请求。");
}
public void send() {
System.out.println("具体同事类2发出请求。");
mediator.relay(this); //请中介者转发
}
}
程序的运行结果如下:
具体同事类1发出请求。
具体同事类2收到请求。
-------------
具体同事类2发出请求。
具体同事类1收到请求。
应用场景
前面分析了中介者模式的结构与特点,下面分析其以下应用场景。
当对象之间存在复杂的网状结构关系而导致依赖关系混乱且难以复用时。
当想创建一个运行于多个类之间的对象,又不想生成新的子类时。
java源码中的体现
在看其他人写的关于Timer 的中介者设计模式,我觉得写的都不是很清楚。我大概用源码来解释一下,顺便再分析一下Timer的所有关联类的源码:
private void sched(TimerTask task, long time, long period) {
if (time < 0)
throw new IllegalArgumentException("Illegal execution time.");
// Constrain value of period sufficiently to prevent numeric
// overflow while still being effectively infinitely large.
if (Math.abs(period) > (Long.MAX_VALUE >> 1))
period >>= 1;
synchronized(queue) {
if (!thread.newTasksMayBeScheduled)
throw new IllegalStateException("Timer already cancelled.");
synchronized(task.lock) {
if (task.state != TimerTask.VIRGIN)
throw new IllegalStateException(
"Task already scheduled or cancelled");
task.nextExecutionTime = time;
task.period = period;
task.state = TimerTask.SCHEDULED;
}
queue.add(task);
if (queue.getMin() == task)
queue.notify();
}
}
说明:所有的schedule方法都调用了sched ,那这个类的主要作用是啥呢?
将timertask加入到队列里,然后从队列里取出min任务(二叉堆的数据结构,下面会说明),判断如果min任务等于当前任务的话让队列wait的状态变为运行状态,如果不等于的话,那么线程的mainloop方法肯定是一直再运行状态的,其他任务就可以依次执行
看如下的源码
private void mainLoop() {
while (true) {
try {
TimerTask task;
boolean taskFired;
synchronized(queue) {
// Wait for queue to become non-empty
while (queue.isEmpty() && newTasksMayBeScheduled)
queue.wait();
if (queue.isEmpty())
break; // Queue is empty and will forever remain; die
// Queue nonempty; look at first evt and do the right thing
long currentTime, executionTime;
task = queue.getMin();
synchronized(task.lock) {
if (task.state == TimerTask.CANCELLED) {
queue.removeMin();
continue; // No action required, poll queue again
}
currentTime = System.currentTimeMillis();
executionTime = task.nextExecutionTime;
if (taskFired = (executionTime<=currentTime)) {
if (task.period == 0) { // Non-repeating, remove
queue.removeMin();
task.state = TimerTask.EXECUTED;
} else { // Repeating task, reschedule
queue.rescheduleMin(
task.period<0 ? currentTime - task.period
: executionTime + task.period);
}
}
}
if (!taskFired) // Task hasn't yet fired; wait
queue.wait(executionTime - currentTime);
}
if (taskFired) // Task fired; run it, holding no locks
task.run();
} catch(InterruptedException e) {
}
}
}
Timer相当于中介者来执行队列里的任务,用户只管将任务抛给timer就可以了。
如下详细timer源码分析
在Java中,很常见的一个定时器的实现就是 Timer 类,用来实现定时、延迟执行、周期性执行任务的功能。
Timer 是定义在 java.util 中的一个工具类,提供简单的实现定时器的功能。和它配合使用的,是 TimerTask 类,这是对一个可以被调度的任务的封装。使用起来非常简单,如下示例:
// 定义一个可调度的任务,继承自 TimerTask
class FooTimerTask extends TimerTask {
@Override
public void run() {
// do your things
}
}
// 初始化Timer 定时器对象
Timer timer = new Timer("barTimer");
// 初始化需要被调度的任务对象
TimerTask task = new FooTimerTask();
// 调度任务。延迟1000毫秒后执行,之后每2000毫秒定时执行一次
timer.schedule(task, 1000, 2000);
以上,就是一个简单的使用Timer 的示例,下文将会分析Timer的源码实现。
概述
在Timer 机制中,涉及到的关键类如下:
- Timer: 主要的调用的,提供对外的API;
- TimerTask: 是一个抽象类,定义一个任务,继承自Runnable
- TimerThread: 继承自 Thread,是一个自定义的线程类;
- TaskQueue: 一个任务队列,包含有当前Timer的所有任务,内部使用二叉堆来实现。
以上几个关键类的引用关系如下: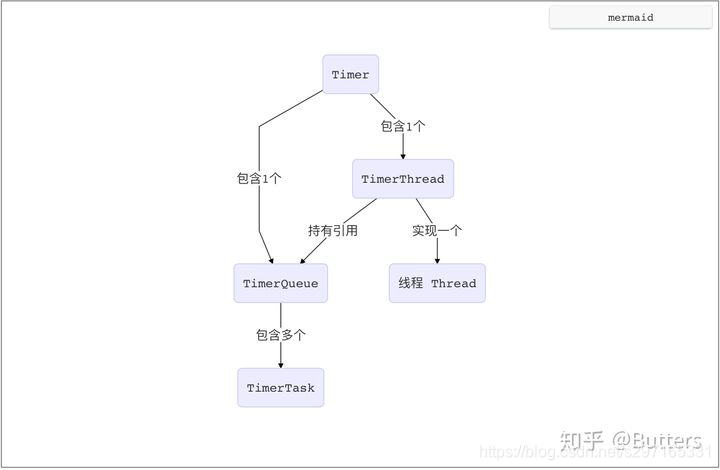
简要描述的话,是:
1个 TimerThread —-> 实现1个 线程
1个 Timer对象 —-> 持有1个 TimerThread 对象
1个 Timer对象 —-> 持有1个 TimerQueue 对象
1个 TimerQueue 对象 —-> 持有 n个 TimerTask 对象
源码分析
Timer类的源码分析
源码分析的话,我们最好是按照Timer 的使用流程来分析。 首先,是Timer 的创建:
// Timer有四个构造方法,但是本质上其实是做的相同的事情,即
// 1. 使用name 和 isDeamon 两个参数给 thread 对象做了参数设置;
// 2. 调用 thread 的 start() 方法启动线程
public Timer() {
this("" + serialNumber());
}
public Timer(boolean isDaemon) {
this("" + serialNumber(), isDaemon);
}
public Timer(String name) {
thread.setName(name);
thread.start();
}
public Timer(String name, boolean isDaemon) {
thread.setName(name);
thread.setDaemon(isDaemon);
thread.start();
}
那么,或许大家会有一个疑问,thread 成员的初始化呢?这个时候,在代码里面找,就能发现:
// 这两个成员都是直接在声明的时候进行了初始化。
private final TaskQueue queue = new TaskQueue();
private final TimerThread thread = new TimerThread(queue);
可以看到 thread 和 queue两个成员都是在声明的时候直接初始化的,并且有意思的是,两个成员都是 final 类型的,这也就意味着这两个成员一旦创建就不会再改了,等于说把 thread、queue 和 Timer 对象这三者的生命周期强行绑定在一起了,大家一起创建,并且一经创建将会无法改变。
然后,创建了Timer 后,与之相关的队列也已经创建成功,而且相关联的线程也启动了,就可以进行任务的调度了,我们看下它的任务调度方法:
// Timer 包含有一组重载方法,参数为以下几个:
// 1. TimerTask task:需要被调度的任务
// 2. long delay: 指定延迟的时间;
// 3. long period: 指定调度的执行周期;
schedule(TimerTask task, long delay, long period)
多个重载的调度方法在经过一些一些列的状态判断、参数设置、以及把delay时间转换成实际的执行时间等之后, 最终完成该功能的是 sched 方法,详情见注释部分:
这里涉及到一个需要留意的点,是在调用schedule 方法的时候,会根据TimerTask 的类型来进行不同的计算,进而给TimerTask设置不同的 period 参数,TimerTask 的类型有以下几种:
- 非周期性任务;对应 TimerTask.period 值为0;
- 周期性任务,但是没有delay值,即立即执行;对应 TimerTask.period 值为正数;
- 周期性任务,同时包含有 delay值;对应 TimerTask.period 值为负数;
在schedule 方法中,会
// 执行任务调度的方法
// 这里的 time 已经是经过转换的,表示该task 需要被执行的时间戳
private void sched(TimerTask task, long time, long period) {
// 参数的合法性检查
if (time < 0)
throw new IllegalArgumentException("Illegal execution time.");
if (Math.abs(period) > (Long.MAX_VALUE >> 1))
period >>= 1;
// 核心的调度逻辑
// 由于是在多线程环境中使用的,这里为了保证线程安全,使用的是 synchronized 代码段
// 对象锁使用的是在 Timer 对象中唯一存在的 queue 对象
synchronized(queue) {
// thread.newTasksMayBeScheduled 是一个标识位,在timer cancel之后 或者 thread 被停止后该标识位会被设为false
// newTasksMayBeScheduled 为false 则表示该timer 的关联线程已经停止了。
if (!thread.newTasksMayBeScheduled)
throw new IllegalStateException("Timer already cancelled.");
// 这里是把外部的参数,如执行时间点、执行周期、设置状态等等。
// 这里为了线程安全的考虑,使用对 task 内部的 lock 对象加锁来保证。
synchronized(task.lock) {
if (task.state != TimerTask.VIRGIN)
throw new IllegalStateException(
"Task already scheduled or cancelled");
task.nextExecutionTime = time;
task.period = period;
task.state = TimerTask.SCHEDULED;
}
// 最后,把新的 task 添加到关联队列里面
queue.add(task);
// 这里,会使用打 TimerQueue 对象的 getMin() 方法,这个方法是获取到接下来将要被执行的TimerTask 对象
// 这里的逻辑是check 新添加的 task 对象是不是接下来马上会被执行
// 如果刚添加的对象是需要马上执行的话,会使用 queue.notify 来通知在等待的线程。
// 那么,会有谁在等待这个 notify 呢?是TimerThread 内部,TimerThread 会有一个死循环,在不停从queue中取任务来执行
// 当queue为空的时候,TimerThread 会进行 queue.wait() 来进行休眠的状态,直到有新的来任务来唤醒它
// 下面的代码就是,当queue为空的时候,这个判断条件会成立,然后就通知 TimerThread 重新唤醒
// 当然,下面的条件成立也不全是 queue 为空的情况下
if (queue.getMin() == task)
queue.notify();
}
}
TimerTask 的源码分析
接下来,本文将会分析 TimerTask 的源码。相对于Timer 来说,它的源码其实很简单,TimerTask 是实现了Runnable 接口,同时也是一个抽象类,它并没有对 Runnable 的 run() 方法提供实现,而是需要子类来实现。
它对外提供了以下几个功能:
包含有一段可以执行的代码(实现的Runnable 接口的run方法)
包含状态的定义。它有一个固定的状态:VIRGIN(新创建)、SCHEDULED(被调度进某一个 timer 的队列中了,但是还没有执行到)、EXECUTED(以及执行过了)、CANCELLED(任务被取消了)。
包含有取消的方法。
包含有获取下一次执行时间的方法。
相关的源码如下:
// 取消该任务
public boolean cancel() {
synchronized(lock) {
boolean result = (state == SCHEDULED);
state = CANCELLED;
return result;
}
}
// 根据执行周期,和设置的执行时间,来确定Task的下一次执行时间。
public long scheduledExecutionTime() {
synchronized(lock) {
// 其中,period 的值分为3种情况:
// 取值为0: 表示该Task是非周期性任务;
// 取值为正数: 表示该Task 是立即执行没有delay的周期性任务,period 的数值表示该Task 的周期
// 取值为负数: 表示该Task 是有 delay 的周期性任务,period 相反数是该Task 的周期
return (period < 0 ? nextExecutionTime + period
: nextExecutionTime - period);
}
}
TimerThread 的源码分析
TimerThread 首先是一个 Thread 的子类,而且我们知道,在Java中,一个Thread 的对象就是代表了一个JVM虚拟机线程。那么,这个 TimerThread 其实也就是一个线程。
对于一个线程来说,那么它的关键就是它的 run() 方法,在调用线程的 start() 方法启动线程之后,接下来就会执行线程的 run() 方法,我们看下 TimerThread 的run() 方法:
public void run() {
try {
// 启动 mainLoop() 方法,这是一个阻塞方法,正常情况下会一只阻塞在这里
// 当 mainLoop() 执行完毕的时候,也即是这个线程退出的时候。
mainLoop();
} finally {
// Someone killed this Thread, behave as if Timer cancelled
// 做一些收尾工作
synchronized(queue) {
newTasksMayBeScheduled = false;
queue.clear(); // Eliminate obsolete references
}
}
}
从以上可以明确得看出,TimerThread 里的实现是调用 mainLoop() 启动了一个死循环,这个死循环内部的工作就是这个线程的具体工作了,一旦线程的死循环执行完毕,线程的 run 方法就执行完了,线程紧接着就退出了。熟悉Android的朋友可能已经觉得这里的实现非常眼熟了,没错,这里的实现和Android平台的 Handler + HandlerThread + Looper 的机制非常相像,可以认为Android平台最初研发这套机制的时候,就是参考的Timer 的机制,然后在上面做了些升级和适合Android平台的一些改动。
下面是 mainLoop() 方法:
private void mainLoop() {
// 一个死循环
while (true) {
try {
TimerTask task;
boolean taskFired;
synchronized(queue) {
// 会等待到队列不为空,结合上面章节的分析,我们可以确定在新添加 TimerTask 到queue中的时候
// 会触发到 queue.notify() 然后通知到这里。
while (queue.isEmpty() && newTasksMayBeScheduled)
queue.wait();
// queue 为空,说明 timer 被取消了
if (queue.isEmpty())
break; // Queue is empty and will forever remain; die
long currentTime, executionTime;
// 又一次看到这个 queue.getMin() ,这个是根据接下来的执行时间来获取下一个需要被执行的任务
task = queue.getMin();
// 需要修改 task对象的内部数值,使用synchronized 保证线程安全
synchronized(task.lock) {
// TimerTask 有多种状态,一旦一个 TimerTask 被取消之后,它就不会被执行了。
if (task.state == TimerTask.CANCELLED) {
queue.removeMin();
continue; // No action required, poll queue again
}
// 获取到当前时间,和这个取出来的task 的下一次执行时间
currentTime = System.currentTimeMillis();
executionTime = task.nextExecutionTime;
// 这里会check 当前这个 task 是不是已经到时间了
// 这里会把是否到时间了这个状态保存在 taskFired 里面
if (taskFired = (executionTime<=currentTime)) {
// 根据上文的分析,TimerTask 根据 task.period 值的不同,被分为3种类型
// 这里的 task.period == 0 的情况,是对应于一个非周期性任务
if (task.period == 0) {
// 非周期性任务,处理完就完事了,改状态,移除队列
queue.removeMin();
task.state = TimerTask.EXECUTED;
} else {
// 周期性任务,会被重新调度,也不会被移除队列
queue.rescheduleMin(
task.period<0 ? currentTime - task.period
: executionTime + task.period);
}
}
}
// 这里是另一个会等待的地方,这个是为了等待任务的到期,等待时间就是距离到执行之间的时长
if (!taskFired)
queue.wait(executionTime - currentTime);
}
// taskFired 变量经过上面的步骤以及判断过了,如果是 true,说明task以及到时间了
// 到时间就运行完事。
if (taskFired)
task.run();
} catch(InterruptedException e) {
}
}
}
TimerThread 中除了上面的主要逻辑之外,还有一些需要关注的地方,那就是它持有一个 TimerQueue 的对象,这个对象是在创建的时候外部传进来的,也是和当前的Timer 关联的TimerQueue:
// 这里的官方注释,说明了为什么是在TimerThread 中引用了 TimerQueue而不是引用了 Timer。
// 这么做是为了避免循环引用(因为Timer中引用了TimerThread),进而避免循环引用可能导致的JVM gc 失败的问题
// 我们都知道,Java 是一门通用的语言,虽然官方的HotSpot JVM中是能解决循环引用的GC问题的,但是这并不意味着
// 其他第三方的JVM也能解决循环引用导致的GC问题,所以这里干脆就避免了循环引用。
/**
* Our Timer's queue. We store this reference in preference to
* a reference to the Timer so the reference graph remains acyclic.
* Otherwise, the Timer would never be garbage-collected and this
* thread would never go away.
*/
private TaskQueue queue;
TimerQueue 的源码分析(主要是实现一个二叉堆)
TimerQueue 的逻辑上是一个队列,所有它包含有一个队列常见的那些方法,如 size()、add()、clear()等方法。下面我们找一些重要的方法进行分析:
首先,在上文的分析中,我们以及见过TimeQueue 的 getMin() 方法了,这个方法是获取当前的队列里面,接下来应该被执行的TimerTask,也就是说,是执行时间点 数值最小的那一个,那么我们就先看下它的源码:
/**
* Return the "head task" of the priority queue. (The head task is an
* task with the lowest nextExecutionTime.)
*/
TimerTask getMin() {
return queue[1];
}
What??? 就这吗?为啥这么简单?为啥就返回 queue[1] 就对了?
你是不是也有这样的疑问,那么带着疑问往下看吧。
接下来,是添加一个TimerTask 到队列中:
// 内部存放TimerTask 数据的,是一个数组,设置的数组初始大小是128
private TimerTask[] queue = new TimerTask[128];
// 存放当前的TimerTask 的数量
// 而且 TimerTask 是存放在 [1 - size] 位置的,数组的第0位置没有数据
// 至于为什么要 存放在 [1 - size] 请看下文。
private int size = 0;
/**
* Adds a new task to the priority queue.
*/
void add(TimerTask task) {
// check 下数据的容量是否还够添加,不够的话会先进行数组的扩容
// 这扩容一次就是2倍增加
if (size + 1 == queue.length)
queue = Arrays.copyOf(queue, 2*queue.length);
// 把新的TimerTask 放在数组的最后一个位置
// size 的初始化值是0,从这里可以看出来,这里会先把size自增1,然后再添加到数组中
// 其实是从数组位置的 1 开始添加 TimerTask 的,0的位置是空的
queue[++size] = task;
// 然后调用了这个数据上浮的方法
fixUp(size);
}
从上文看出,add 方法本身也没什么奇特的,就是很简单地把新的 TimerTask 放在了数据的最新的位置,只是里面调用了一下另一个方法 fixUp() ,好,那么我们接着分析这个方法:
// 从上文可以看出,参数 k 是当前的数组size 值,也是最后一个TimerTask 的下标索引
private void fixUp(int k) {
// 首先,这是一个循环,循环条件是 k > 1
while (k > 1) {
// 位运算,操作,把 k 右移一位,得到的结果是:偶数相当于除以2,奇数相当于先减1再除以2
int j = k >> 1;
// 比较 j 和 k 两个位置的下次执行时间,j 不大于 k 的话,就停止循环了
if (queue[j].nextExecutionTime <= queue[k].nextExecutionTime)
break;
// j 大于 k 位置的时间的话,就要进行下面的动作
// 这是一个典型的交换操作
TimerTask tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp;
// k 值缩小到j,去逼近循环条件 k>1
k = j;
}
}
看了上面对 fixUp() 的分析,是不是仍然一脸懵?或许也有些熟悉算法的朋友已经觉察出些什么了,那么这个地方的逻辑是什么呢?
有了右移一位、[1, size]的区间等蛛丝马迹,我想聪明的你已经猜出来了,这个数组queue 里面,是存放了一个完全二叉树。
在发现 queue 数组是一个二叉树之后,再去理解上面的 fixUp() 方法其实就很简单了,里面的过程是这样的:
从二叉树的最后一个叶子结点开始循环;
获取这个叶子结点的父结点(完全二叉树中对应的父结点的索引是:子结点位运算右移一位得到的)
判断父结点和子结点中对应的 TimerTask 的 nextExecutionTime 的大小,如果父比子的小,则停止循环;如果父比子的大,则交互负责结点;
重复以上循环,直到遍历到根结点;
通过以上分析,能发现在每一次新增一个结点后,使用 fixUp(),方法直接对整个二叉树进行了重排序,使得 TimerTask 的nextExecutionTime 值最小的结点,永远被放置在了二叉树的根结点上,也即是queue[1]。这也就搞明白了为什么 getMin 的实现,是直接获取的 queue[1] 。
同样的道理,在每一次执行 Timer.purge() 方法,清理了TimerQueue中已经取消的Task之后,会执行另一个 fixDown() 方法,它的逻辑正好是和 fixUp() 相反的,它是从根结点开始遍历的,然后到达每一个叶子结点以整理这个二叉树,这里就不再赘述。
回过头来,我们再看下TimerQueue中的实现,会发现它其实是一个二叉堆,二叉堆是一个带有权重的二叉树,这里不再多说。
总结
通过以上的分析,总的来说,就是每一个 Timer对象中,包含有一个线程(TaskThread)和一个队列(TaskQueue)。TaskQueue 的实现是一个二叉堆(Binary Heap)的结构,二叉堆的每一个节点,就是 TimerTask 的对象。
