前言:
最近在公司的一个项目中遇到了一个需求,就是将读取到的JSON数据,展示成一个树形结构,并且还得给每一个节点添加一个类型标签以及复选框。好了,话不多说,直接上代码,代码的思路到时候放在代码后面。如果各位看官老爷觉得有什么可以优化的地方或者不理解的地方也可以在评论中说出,大家一起讨论;
代码
<script>
export default {
name: "YJsonEditer",
data() {
return {
JsonAST: {},
LiList: [],
checkBoxList: [],
checkBoxKey: 1,
// checkId:''
};
},
props: {
json: {
type: String,
default:
'{"total":18,"data":[[{"themeType":{"themeType":"dark"}}],[{"themeType":"light"}]],"rows":[{"caseCode":"9174ff6dfbc243eb931270a06c447666","institutionId":2,"arbitralCourtId":1,"nickName":"张慧","deptId":102,"applicantName":"钱红","arbitralCourtName":"第一仲裁庭","times":2,"caseNumber":"常钟劳人仲案字〔2023〕第29号","scheduleDate":"2023-05-30T00:00:00","caseName":"钱红讨薪","respondentName":"钱橙","startTime":"08:30:00","id":26,"endTime":"08:45:00","status":"1"},{"caseCode":"1c096b703b78495ea90ca13ab65258cb","institutionId":2,"arbitralCourtId":1,"nickName":"徐洋","deptId":102,"applicantName":"赵春","arbitralCourtName":"第一仲裁庭","times":1,"caseNumber":"常钟劳人仲案字〔2023〕第28号","scheduleDate":"2023-05-25T00:00:00","caseName":"赵春徐洋登记","respondentName":"赵夏","startTime":"08:30:00","id":24,"endTime":"08:45:00","status":"3"},{"caseCode":"9174ff6dfbc243eb931270a06c447666","institutionId":2,"arbitralCourtId":1,"nickName":"张慧","deptId":102,"applicantName":"钱红","arbitralCourtName":"第一仲裁庭","times":1,"caseNumber":"常钟劳人仲案字〔2023〕第29号","scheduleDate":"2023-05-25T00:00:00","caseName":"钱红讨薪","respondentName":"钱橙","startTime":"09:00:00","id":25,"endTime":"09:15:00","status":"3"},{"caseCode":"47cdbb573f354660b448d3bf55d36a69","arbitralCourtId":1,"nickName":"徐洋","applicantName":"赵春","arbitralCourtName":"第一仲裁庭","times":1,"caseNumber":"常钟劳人仲案字〔2023〕第26号","scheduleDate":"2023-05-24T00:00:00","caseName":"劳动报酬","respondentName":"赵夏","startTime":"08:30:00","id":23,"endTime":"08:45:00","status":"3"},{"caseCode":"e3a68febb9294112a85dfeffc00002d6","arbitralCourtId":1,"nickName":"周圆","applicantName":"申请人加密","arbitralCourtName":"第一仲裁庭","respondentCompanyName":"被申请单位加密","times":3,"caseNumber":"常钟劳人仲案字〔2023〕第12号","scheduleDate":"2023-05-23T00:00:00","caseName":"测试加密1111","startTime":"18:30:00","id":22,"endTime":"18:45:00","status":"3"},{"caseCode":"e3a68febb9294112a85dfeffc00002d6","arbitralCourtId":1,"nickName":"周圆","applicantName":"申请人加密","arbitralCourtName":"第一仲裁庭","respondentCompanyName":"被申请单位加密","times":2,"caseNumber":"常钟劳人仲案字〔2023〕第12号","scheduleDate":"2023-05-19T00:00:00","caseName":"测试加密1111","startTime":"08:45:00","id":21,"endTime":"09:15:00","status":"2"},{"caseCode":"9ae48862deaa4c24982b8bef5993d00d","arbitralCourtId":1,"nickName":"徐洋","applicantName":"数据库加密申请人1,申请人2","arbitralCourtName":"第一仲裁庭","respondentCompanyName":"数据库加密单位","times":1,"caseNumber":"常钟劳人仲案字〔2023〕第11号","scheduleDate":"2023-05-12T00:00:00","caseName":"加密测试案件","startTime":"09:00:00","id":19,"endTime":"09:30:00","status":"1"},{"caseCode":"e3a68febb9294112a85dfeffc00002d6","arbitralCourtId":1,"nickName":"周圆","applicantName":"申请人加密","arbitralCourtName":"第一仲裁庭","respondentCompanyName":"被申请单位加密","times":1,"caseNumber":"常钟劳人仲案字〔2023〕第12号","scheduleDate":"2023-05-12T00:00:00","caseName":"测试加密1111","startTime":"12:30:00","id":20,"endTime":"15:00:00","status":"1"},{"caseCode":"73c606f4dfca4137b3c0f4ee6ed4b9f9","institutionId":2,"arbitralCourtId":1,"nickName":"姜哲","deptId":102,"arbitralCourtName":"第一仲裁庭","times":1,"caseNumber":"常钟劳人仲案字〔2023〕第3号","scheduleDate":"2023-05-05T00:00:00","caseName":"赔偿医疗费","startTime":"08:30:00","id":18,"endTime":"08:45:00","status":"3"},{"caseCode":"793855c4cab545099752d7b4dd2ef402","times":1,"arbitralCourtId":1,"caseNumber":"常钟劳人仲案字〔2023〕第10号","nickName":"刘祥任","scheduleDate":"2023-05-04T00:00:00","caseName":"某某公司拖欠工资","startTime":"09:00:00","id":16,"endTime":"09:30:00","arbitralCourtName":"第一仲裁庭","status":"1"}],"code":200,"msg":"查询成功"}',
},
height: {
type: String,
default: "100%",
},
width: {
type: String,
default: "100%",
},
checkId: {
type: String,
default: "",
},
isEdit: {
type: Boolean,
},
},
methods: {
/**
* @description 初始化JSON数据,将其变成AST树;
*/
initJSON() {
// console.log(this.json)
if (!this.json) return;
let jsonObj = JSON.parse(this.json);
this.JsonAST = {
label: "",
type: "Object",
_id: "0",
isExpand: true,
children: this.JsonRecursionToAst(jsonObj, "0"),
};
},
/**
* @description 递归处理JSON数据,返回AST树;
*/
JsonRecursionToAst(jsonVal, _parentId, _parentKey) {
let _type = this.getType(jsonVal);
let currentArr = [];
// 通过传入类型决策使用
let _typeDecision = {
Array: () => {
if (jsonVal.length != 0) {
jsonVal.forEach((item, idx) => {
let current = {
label: String(idx),
_id: `${_parentId}-${idx}`,
type: this.getType(item),
_key: `${_parentKey}[${idx}]`,
};
if (current.type == "Object" || current.type == "Array") {
current.isExpand = true;
current.children = this.JsonRecursionToAst(
item,
current._id,
current._key
);
}
currentArr.push(current);
});
}
return currentArr;
},
Object: () => {
let currentKeys = Object.keys(jsonVal);
if (currentKeys.length != 0) {
currentKeys.forEach((key, idx) => {
let current = {
label: key,
_id: `${_parentId}-${idx}`,
type: this.getType(jsonVal[key]),
_key: `${_parentKey ? _parentKey + "." : ""}${key}`,
};
if (current.type == "Object" || current.type == "Array") {
current.isExpand = true;
current.children = this.JsonRecursionToAst(
jsonVal[key],
current._id,
current._key
);
}
currentArr.push(current);
});
}
return currentArr;
},
};
return _typeDecision[_type]();
},
/**
* @description 将AST语法树转换为显示List
*/
AstRecursionToList(AstTree) {
let list = [];
let _type = this.getType(AstTree);
let _typeDecision = {
Array: () => {
AstTree.forEach((_node) => {
const { label, type, _id, _key } = _node;
if (type == "Array" || type == "Object") {
const { isExpand, children } = _node;
if (isExpand) {
const chileList = this.AstRecursionToList(children) ?? [];
chileList.unshift({
label,
type,
_id,
isExpand,
_key,
});
chileList.push({
endTag: true,
_id,
type,
});
list = list.concat(chileList);
} else {
list.push({ label, type, _id, isExpand, children, _key });
}
} else {
list.push({ label, type, _id, _key });
}
});
return list;
},
Object: () => {
const { label, type, _id, _key } = AstTree;
if (type == "Array" || type == "Object") {
const { isExpand, children } = AstTree;
// 如果展开标志位为true,则继续递归,否则不进行递归
if (isExpand) {
const chileList = this.AstRecursionToList(children) ?? [];
chileList.unshift({
label,
type,
_id,
isExpand,
_key,
});
chileList.push({
endTag: true,
type,
_id,
});
list = list.concat(chileList);
} else {
list.push({ label, type, _id, isExpand, _key });
}
} else {
list.push({ label, type, _id, _key });
}
return list;
},
};
return _typeDecision[_type] && _typeDecision[_type]();
},
/**
* @descripotion 修改AST语法树中isExpand状态
*/
changeIsExpandInAst(tree, id) {
let _type = this.getType(tree);
let _typeDecision = {
Array: () => {
tree.forEach((node) => {
const { type, _id } = node;
if (_id == id) {
node.isExpand = !node.isExpand;
return;
}
// 如果当前层级拥有子级,并且id前缀可以匹配,则进行递归
if (
(type == "Object" || type == "Array") &&
Object.hasOwnProperty.call(node, "children") &&
id.indexOf(_id) > -1
) {
this.changeIsExpandInAst(node.children, id);
}
});
},
Object: () => {
const { _id } = tree;
// 如果匹配,则直接修改状态并返回
if (_id == id) {
tree.isExpand = !tree.isExpand;
return;
}
// 如果当前层级拥有子级,并且id前缀可以匹配,则进行递归
if (Object.hasOwnProperty.call(tree, "children") && id.indexOf(_id) > -1) {
this.changeIsExpandInAst(tree.children, id);
}
},
};
_typeDecision[_type]();
},
/**
* @description 获取数据类型
*/
getType(val) {
const type = Object.prototype.toString
.call(val)
.replace("[object ", "")
.replace("]", "");
return type == "Null" ? "String" : type;
},
/**
* @description 获取缩进长度,默认靠左多2em
*/
getIndentation(id) {
return id?.split("-")?.length * 2 ?? 2;
},
getCheckStatus(id) {
const flag = this.checkBoxList.filter((checkBox) => checkBox == id).length != 0;
if (flag) {
return true;
} else {
return false;
}
},
checkChange(e, id, key, label) {
if (Array.from(id).length == 0) return;
this.checkBoxKey += 1;
if (e) {
if (this.checkBoxList.length == 0 || this.checkBoxList.length == 1) {
this.checkBoxList = this.createIdsFromNodeId(id);
} else {
// 设置是否允许修改标志位
let canEdit = true;
let checkList = this.createIdsFromNodeId(id);
if (checkList.length < this.checkBoxList.length) {
this.$message.warning("请先取消已选中的同级字段,在进行勾选");
return;
}
for (let index = 0; index < this.checkBoxList.length - 1; index++) {
const element = this.checkBoxList[index];
if (element != checkList[index]) {
canEdit = false;
}
}
if (canEdit) {
this.checkBoxList = checkList;
} else {
this.$message.warning("请先取消已选中的同级字段,在进行勾选");
}
}
} else {
let canEdit = this.checkBoxList.filter((box) => box == id).length != 0;
if (canEdit) {
let checkBoxList = this.createIdsFromNodeId(id);
checkBoxList.pop();
this.checkBoxList = checkBoxList;
} else {
this.$message.warning("请先取消已选中的同级字段,在进行勾选");
}
}
const c_id = this.checkBoxList?.slice(-1)[0];
c_id == this.checkId ? "" : this.getKeyAndId(c_id);
},
//返回path id
getKeyAndId(id) {
const obj = this.LiList.find((item) => item._id == id);
obj ? this.$emit("change", { path: obj._key, id: obj._id }) : "";
},
/**
* @description 根据id生成数组
*/
createIdsFromNodeId(id) {
let list = [];
id.split("-").forEach((item) => {
if (list.length == 0) {
list.push(item);
} else {
list.push(`${list[list.length - 1]}-${item}`);
}
});
return list;
},
/**
* 预览模式设置选中元素
*/
setcheckId() {
const { checkId } = this;
this.checkChange(true, checkId ?? "");
},
},
watch: {
checkId(e) {
console.log(e);
},
json: {
handler(val) {
if (typeof val == "string") {
this.initJSON();
} else {
// 如果传入的值不为JSON格式,抛异常
console.error("inputDataType not JSON!");
}
},
immediate: true,
deep: true,
},
JsonAST: {
handler(val) {
this.LiList = this.AstRecursionToList(val);
this.$nextTick(() => {
this.setcheckId();
});
},
immediate: true,
deep: true,
},
},
render() {
// 单独生成一行html
let singLineHtml = (_node) => {
// const {label, type, _id} = _node;
return (
<div style={{ textIndent: `${this.getIndentation(_node._id)}em` }}>
{createLabel(_node)}
{createTypeTag(_node)}
{createExpandTag(_node)}
{createBracket(_node)}
{createCheckBox(_node)}
</div>
);
};
let createLabel = (_node) => {
if (Object.hasOwnProperty.call(_node, "label") && _node.label?.length != 0) {
return <span>{`"${_node.label}":`}</span>;
}
};
let createExpandTag = (_node) => {
if (Object.hasOwnProperty.call(_node, "isExpand")) {
const { isExpand, _id } = _node;
return (
<i
onClick={() => {
this.changeIsExpandInAst(this.JsonAST, _id);
}}
style="color:#ff9a00;"
class={
isExpand
? "el-icon-remove-outline expandTag"
: "el-icon-circle-plus-outline expandTag"
}
></i>
);
}
};
let createTypeTag = (_node) => {
if (!Object.hasOwnProperty.call(_node, "endTag")) {
const { type } = _node;
return <span class={`tag ${type}-tag`}>{type}</span>;
}
};
let createBracket = (_node) => {
const { type } = _node;
if (Object.hasOwnProperty.call(_node, "endTag")) {
if (type == "Array") {
return (
<span>
<span class="bracket-array">{"]"}</span>,
</span>
);
} else {
return (
<span>
<span class="bracket-object">{"}"}</span>,
</span>
);
}
} else if (Object.hasOwnProperty.call(_node, "isExpand")) {
const { isExpand } = _node;
// 展开
let expandStrategy = {
Array: () => {
return (
<span>
<span class="bracket-array">{"["}</span>
</span>
);
},
Object: () => {
return (
<span>
<span class="bracket-object">{"{"}</span>
</span>
);
},
};
// 关闭
let notExpandStrategy = {
Array: () => {
return (
<span>
<span class="bracket-array">{`[${_node.children.length}]`}</span>,
</span>
);
},
Object: () => {
return (
<span>
<span class="bracket-object">{"{...}"}</span>,
</span>
);
},
};
return isExpand ? expandStrategy[type]() : notExpandStrategy[type]();
} else {
return <span>,</span>;
}
};
let createCheckBox = (_node) => {
if (!Object.hasOwnProperty.call(_node, "endTag")) {
const { _id, _key, label } = _node;
return (
<el-checkbox
key={this.checkBoxKey}
style={this.isEdit ? "pointer-events:none" : ""}
value={this.getCheckStatus(_id)}
onChange={(e) => {
this.checkChange(e, _id, _key, label);
}}
></el-checkbox>
);
}
};
return (
<ul
class="json-container"
style={{ height: this.height, width: this.width }}
ref="JsonContainer"
>
<div class="json-index"></div>
{this.LiList.map((node, idx) => {
return (
<li>
<span class="line-head">{idx + 1}</span>
{singLineHtml(node)}
</li>
);
})}
</ul>
);
},
};
</script>
<style lang="scss" scoped>
.json-container {
background-color: #fff;
overflow: auto;
color: #767676;
position: relative;
.json-index {
width: 44px;
height: 100%;
background: #f5f5f5;
position: absolute;
top: 0;
left: 0;
// border-right:1px solid #E7E7E7;
}
li {
height: 35px;
line-height: 35px;
display: flex;
font-size: 14px;
position: relative;
.line-head {
display: inline-block;
height: 35px;
line-height: 35px;
width: 44px;
box-sizing: border-box;
font-size: 14px;
text-align: center;
border: solid #e7e7e7;
border-width: 0 1px 1px 0;
background: #f5f5f5;
// &:last-of-type{
// border-width: 0 1px 0px 0;
// }
}
}
}
.tag {
box-sizing: border-box;
padding: 3px 7px;
display: initial;
border-radius: 4px;
margin-left: 2px;
margin-right: 2px;
color: #fff;
background-color: #c9c9c9;
font-size: 12px;
}
.Object-tag {
background-color: #ff9a00;
}
.Number-tag {
background-color: #2b7cf5;
}
.String-tag {
background-color: #00a870;
}
.Array-tag {
background-color: #a17bd1;
}
.bracket-object {
color: #ff9a00;
}
.bracket-array {
color: #a17bd1;
}
.expandTag {
cursor: pointer;
display: initial !important;
}
::v-deep.el-checkbox {
display: initial;
.el-checkbox__input {
display: initial;
}
// .el-checkbox__input.is-disabled.is-checkId .el-checkbox__inner{
// background: #2B7CF5;
// &::after{
// border-color: #FFF;
// }
// }
}
</style>
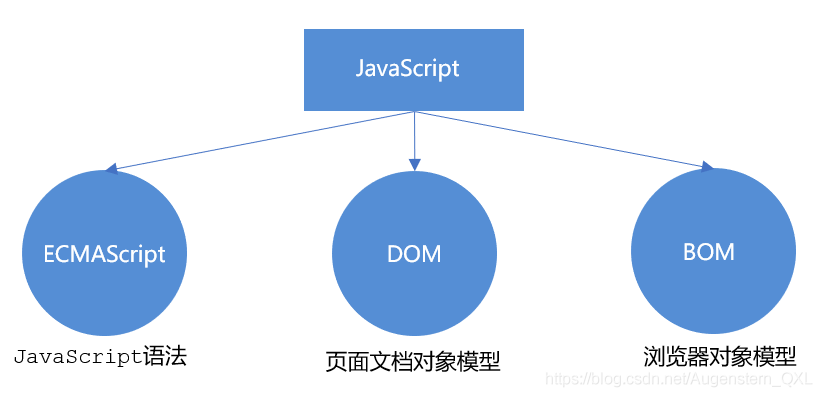
思维导图

主要函数解读
JsonRecursionToAst
这个方法是递归处理传入的JSON数据,首先通过getType方法获取当前节点的数据类型【getType中通过原型链方式获取数据类型】,根据数据类型决策返回数据【主要节点参数是label(key),_id(节点ID),type(节点数据类型),其余的参数为业务需求】;
AstRecursionToList
直接通过AST树去生成DOM结构的话我觉得会比较复杂,所以我就在AST树与DOM结构之间写了此方法,这个方法去监听AST树,只要树发生了变化便会执行次方法;首先进入这个方法后根据节点类型去决策进入哪个结构,然后根据isExpand判断是否展开,若不展开则直接不向下执行,若展开,则继续递归;
changeIsExpandInAst
此方法是修改展开状态的,通过_id进行匹配,只要前缀相同,则递归,直至完全相同修改状态;
checkChange
这个方法是业务逻辑的需求,可以点击节点前的复选框,但是不允许点击不同分支的复选框;







































































































































































































 若不是最近看到这样一篇新闻。
若不是最近看到这样一篇新闻。
 当时机哥身边的亲朋好友,只要是有智能手机的。
当时机哥身边的亲朋好友,只要是有智能手机的。
 原因倒是不复杂,在那个流量资费偏高的年代。
原因倒是不复杂,在那个流量资费偏高的年代。 WiFi万能钥匙,总是能如它的名字般神奇,帮用户成功连上WiFi。
WiFi万能钥匙,总是能如它的名字般神奇,帮用户成功连上WiFi。
 关键是,这软件还免费使用。
关键是,这软件还免费使用。
 WiFi万能钥匙发布不到三年,就拥有超过5亿的激活用户。
WiFi万能钥匙发布不到三年,就拥有超过5亿的激活用户。 什么叫风头无两啊,
什么叫风头无两啊,


 再加上App内部,出现了各种离谱的广告。
再加上App内部,出现了各种离谱的广告。 不知道的,还以为下了个病毒软件呢...
不知道的,还以为下了个病毒软件呢...
 但它这些年,积攒起来的崩坏口碑。
但它这些年,积攒起来的崩坏口碑。
 当然啦,如果只是广告讨人嫌。
当然啦,如果只是广告讨人嫌。
 但它能帮咱们连上各种场合的WiFi,原理并不是暴力破解。
但它能帮咱们连上各种场合的WiFi,原理并不是暴力破解。
 听起来,似乎是个不错的模式对吧。
听起来,似乎是个不错的模式对吧。 你帮我,我帮你,天下就没有难办的事儿了。
你帮我,我帮你,天下就没有难办的事儿了。
 但理想很丰满,现实很骨感。
但理想很丰满,现实很骨感。

 我凭什么无缘无故,给一个陌生人一块钱?
我凭什么无缘无故,给一个陌生人一块钱?
 他表示,App可以直接从用户手机拿到WiFi密码。
他表示,App可以直接从用户手机拿到WiFi密码。
 可谓是明文存放,点开就送。
可谓是明文存放,点开就送。
 可很凑巧的是,早期的安卓手机获取权限非常简单。
可很凑巧的是,早期的安卓手机获取权限非常简单。
 紧接着,最关键的问题来了。
紧接着,最关键的问题来了。
 作为一个,只会输入“Hello World”的代码废柴。
作为一个,只会输入“Hello World”的代码废柴。

 嗯?难道说...
嗯?难道说...
 如果实在遇到一些,数据库里配对不上的WiFi。
如果实在遇到一些,数据库里配对不上的WiFi。
 机友们都懂的,其实很多家庭路由器,密码都设置得很简单。
机友们都懂的,其实很多家庭路由器,密码都设置得很简单。


 “我们可是有9亿用户总量的,欢迎来合作啊喂。
“我们可是有9亿用户总量的,欢迎来合作啊喂。
 不能说克制,只能说处处皆是广告位。
不能说克制,只能说处处皆是广告位。
 而WiFi万能钥匙,对于广告的内容筛选,更是让人汗流浃背。
而WiFi万能钥匙,对于广告的内容筛选,更是让人汗流浃背。

 讲道理,以它如此庞大的用户总量。
讲道理,以它如此庞大的用户总量。 更何况,现在早就不是,流氓App能随意践踏手机的时代了。
更何况,现在早就不是,流氓App能随意践踏手机的时代了。


 结果发现,它现在往App塞了个短剧板块。
结果发现,它现在往App塞了个短剧板块。
 emmm...机哥也没啥好说的,祝它一切顺利吧。
emmm...机哥也没啥好说的,祝它一切顺利吧。

