前段时间,跟好哥们儿商量了一下,帮他公司设计并开发一款宣传用的小程序。因为是宣传用的,所以对于后台数据几乎没什么需求,只需要用到一些接口,引导用户联系公司,且公司性质是古建筑装修,没有自己的服务器。所以我直接给他做的是个静态的小程序。
微信小程序的开发需要注意几个点:
1、主包不大于2M,分包不超过20M。
图片、视频等文件很容易占据大量空间,因此,作为没有服务器的静态页面,这些图片、视频资源,放在什么地方,然后再拿到网络链接地址,是非常关键的节省空间的方案。
2、微信小程序开发者工具,众所周知经常发神经,
莫名其妙弹出一些报错,也会有一些不兼容情况,其中的一些组件也是经常出现问题,比如媒体组件莫名其妙报“渲染层网络错误”的err。
在这次的miniProgram中,有一些功能的实现中,触发了各种奇怪bug。比如
自定义tabbar,
为了让tabbar能被自定义定制,我几乎把整个关于tabbar的开发文档读了个通透;而在定制之后又发现,
pc端模拟机上正常显示、真机预览正常显示,唯独真机调试中,tabbar不显示。
也不是不显示,我的小米8手机不显示,我两位朋友的iphone,一个显示一个不显示(过程中所有的配置是完全相同的)。
接下来就详细介绍一下我在开发中遇到的几个让我把头皮薅到锃亮的问题。
1、自定义tabbar组件
微信小程序app.json中可以直接配置tabbar。但默认的tabbar组件
不足以完全应付各类不尽相同的场景。
譬如,默认的tabbar上使用的icon
实际是png等格式的图片
而非iconfont,其大小也完全由图片本身大小决定,
无法通过css自定制。
为了解决不同业务需求,小程序也非常人性化的
允许tabbar自定义。
其方法如下:
1、在app.json的tabbar配置中,加上custom:true
2、原本的tabbar配置项必须写完整。
在custom:true之后,tabbar的所有样式皆由自定义组件控制(颜色等),但路径等需要填写正确,否则会报错路径找不到。如配置项中必须的属性不写完整,会导致报错,告诉你缺少必须的配置项属性,也不会解析出来。
"custom": true, //自定义tabbar开启
"color": "#c7c7c7", //常态下文字颜色
"selectedColor": "#056f60", //被选中时文字颜色
"list": [
{
"iconPath": "images/tabBarIcon/index.png", //常态下icon图片的路径
"selectedIconPath": "images/tabBarIcon/index-action.png", //被选中时icon图片的路径
"text": "首页展览", //icon图片下的文字
"pagePath": "pages/index/index" //该tabbar对应的路由路径
},
{
"iconPath": "images/tabBarIcon/cases.png",
"selectedIconPath": "images/tabBarIcon/cases-action.png",
"text": "精选案例",
"pagePath": "pages/cases/cases"
},
{
"iconPath": "images/tabBarIcon/about.png",
"selectedIconPath": "images/tabBarIcon/about-action.png",
"text": "关于我们",
"pagePath": "pages/about/about"
},
{
"iconPath": "images/tabBarIcon/contact.png",
"selectedIconPath": "images/tabBarIcon/contact-action.png",
"text": "联系我们",
"pagePath": "pages/contact/contact"
}
]
},
3、创建一个自定义组件文件夹custom-tab-bar。
级别为component组件级别。里面包含一个微信小程序包必须的wxml、wxss、js、json文件。
在这里我使用了vant weapp组件库做的tabbar组件。组件上的icon用的是字节跳动的fontPark字体图标库。
<!-- components/tabBar/tabBar.wxml -->
<!-- active用于控制被选定的item -->
<van-tabbar class="tabbar"
active="{{ active }}"
inactive-color="#b5b5b5"
active-color="#056f60"
bind:change="onChange"
>
<van-tabbar-item class="tabbarItem"
wx:for="{{list}}" wx:key="id">
<view class="main">
<image class="selectedIcon"
src="{{item.selectedIconPath}}"
wx:if="{{item.id === active}}"
mode=""
/>
<image src="{{item.iconPath}}" wx:else mode="" class="icon"/>
<text class="txt">{{item.text}}</text>
</view>
</van-tabbar-item>
</van-tabbar>
/* components/tabBar/tabBar.wxss */
.main{
display: flex;
flex-direction: column;
justify-content:center;
align-items: center;
}
.tabbarItem{
background-color: #e9e9e9;
}
.selectedIcon, .icon{
width: 40rpx;
height: 40rpx;
margin-bottom: 10rpx;
}
Component({
data:{
active:0,
list:[
{
id:0,
iconPath: "/images/tabBarIcon/index.png",
selectedIconPath:"/images/tabBarIcon/index-action.png",
text:"首页展览",
pagePath:"pages/index/index"
},
{
id:1,
iconPath: "/images/tabBarIcon/cases.png",
selectedIconPath:"/images/tabBarIcon/cases-action.png",
text:"精选案例",
pagePath:"pages/cases/cases"
},
{
id:2,
iconPath: "/images/tabBarIcon/about.png",
selectedIconPath:"/images/tabBarIcon/about-action.png",
text:"关于我们",
pagePath:"pages/about/about"
},
{
id:3,
iconPath: "/images/tabBarIcon/contact.png",
selectedIconPath:"/images/tabBarIcon/contact-action.png",
text:"联系我们",
pagePath:"pages/contact/contact"
}
]
},
computed:{
},
methods:{
onChange(event){
if(event.detail===0){
wx.switchTab({
url: '/pages/index/index',
})
}else if(event.detail===1){
wx.switchTab({
url: '/pages/cases/cases',
})
}else if(event.detail===2){
wx.switchTab({
url: '/pages/about/about',
})
}else if(event.detail===3){
wx.switchTab({
url: '/pages/contact/contact',
})
}
}
},
})
到这里完成了页面跳转功能。但会发现,当我们点击其他页面的tab时,并
没有让tabbar的图表发生变化,
始终在首页被选定。
这是因为data中的active并没有发生变化,依然是active:0
那么要解决这个问题,方案是在每个tabbar路由页面的js文件中,修改active的值。比如,当点击首页时,active=0,点击第二个页面cases时,active=1......以此类推。
Page({
onShow() {
if (typeof this.getTabBar === 'function' &&
this.getTabBar()) {
this.getTabBar().setData({
active: 0
})
}
}
})
Page({
onShow() {
if (typeof this.getTabBar === 'function' &&
this.getTabBar()) {
this.getTabBar().setData({
active: 0
})
}
}
})
直到这一步,整个自定义的tabbar组件算是完成。
出现过的BUG
因为tabbar在app.json文件中"tabbar"配置项配置过了,所以不用再在app.json中的usingComponent配置项进行引用。也无需在tabbar的路由页面的json文件中进行页面配置。
我曾在onChange(event){}方法中,添加了一行代码:this.setData({active: event.detail });
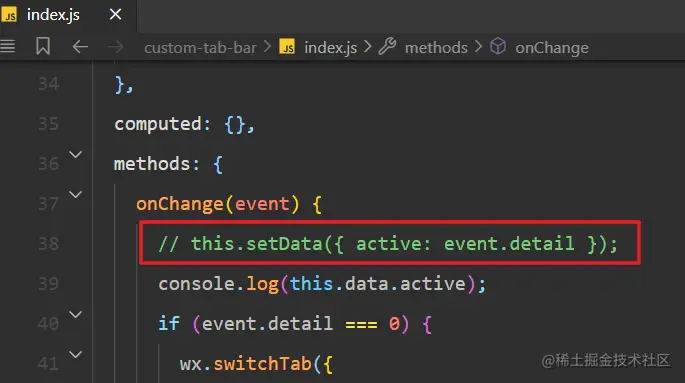
这段代码在没有注释掉的时候,会导致组件在页面切换时发生跳动,处于一种混乱的状态。其原因大致是因为这行代码与page页onshow()时期的getTabBar().setData()有同样的active赋值效果,所以冲突,造成组件闪烁。
- 在整个项目完成后,我在使用真机调试时意外发现,模拟机上的tabbar正常显示并使用,但手机上却消失不见。
PC端:

安卓mi8:
我找了很多帖子,没有发现能解决我问题的方案。然后我就问了前辈。前辈的手机是苹果系统,无论是预览、调试,都可以正常显示并使用tabbar,告知我可能是我手机问题,或许是我的手机有什么权限没开。
我又找到一位用苹果手机的同事。如果这位同事的手机也能正常使用,我就要再找一个安卓机的伙伴再测试一次,看看是否机型对代码有影响。
结果奇怪的是,我的这位朋友在进行真机调试时,也没有正常显示tabbar组件。
那么结果就不是安卓和苹果的系统问题。肯定与代码或者某种权限有关。
于是我花了两三个小时去一点点修改,一遍遍重复调试,直到终于找到问题关键所在:
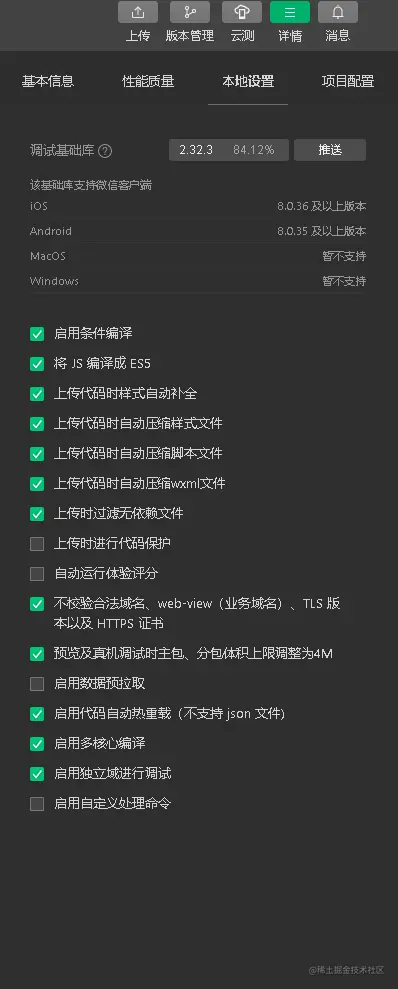
这是微信小程序开发者工具中的详情界面,在本地设置中,有一个
启用条件编译
选项。把这个选项开启,tabbar就显示了;关掉这个选项,tabbar就消失了。
于是我开始搜索启用条件编译是什么意思:
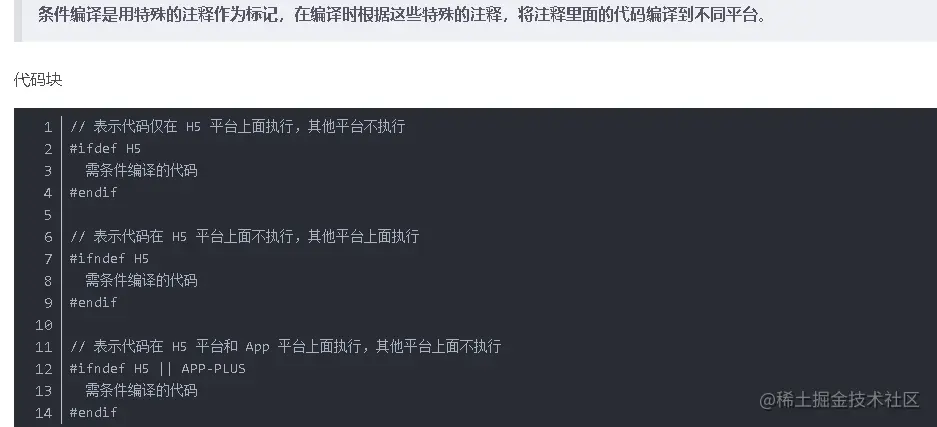
这是最后找到的结果。但是我并不明白为什么勾选这个会对tabbar有影响。都没有勾选的情况下,前辈的苹果手机就有显示,另一位同事的苹果手机又没有显示,而安卓机的我也一样没有显示。
如果有哪位大佬明白其中的原理,请一定要留言告诉我!!!
2、地图系统
地图系统应该是非常常见的功能,如果在公司的宣传类小程序中加入地图系统,会非常便于用户获取地址信息。
地图系统使用很简单,可以说没太大难度。只要给个map容器,然后给上必须的键值对:经(longitude)纬(latitude)度,如果需要,再给个scale,限制地图缩放的级别,其他的都可以在腾讯地图api的文档中查找需要用的属性。
如果小程序中地图没显示,就要去腾讯地图开放平台里面看看。因为这些地图系统的api都是需要密钥才能使用,所以
注册
api开放平台的账户是第一步,然后在上面的开发文档中选择微信小程序SDK中可以查阅文档。在右上角登录旁边有个控制台,里面创建一个实例,把自己的小程序appID填进去,这个时候小程序中的map应该就是可以正常显示并使用了。
如果需要在小程序的地图中加入标记点,就在map中加入markers,js中传入Obj obj格式的参数,就可以了,在腾讯地图的文档内也有。
地图系统并不难,只需要按照api规则来即可。
<map
longitude="不便展示"
latitude="不便展示"
scale="16"
markers="{{markers}}"
enable-zoom="{{false}}"
enable-scroll="{{false}}"
enable-satellite
style="width: 100%;"
/>
Page({
data: {
markers: [{
id: 1,
longitude: 不便展示,
latitude: 不便展示,
iconPath: '/images/local.png',
height: 20,
width: 20,
title: '不便展示',
}],
},
openMap() {
wx.openLocation({
longitude: 不便展示,
latitude: 不便展示,
scale: 18,
name: '不便展示',
});
}
})
3、奇奇怪怪的位置用swiper
一般而言swiper都会用在首页,用以承载轮播图。
不得不说,微信小程序自带的swiper组件虽然简单,但是好用,放上去之后加点属性和数据就可以直接用,比起bug频出的swiper插件还是舒服些。
但是swiper组件就不能用在其他地方吗?
当然可以咯,只要愿意,你就是把许多个业务员的名片用一个swiper组件去收纳,用户不嫌麻烦去一个一个翻的话,你就做呗!
这里,我在精选案例中用了两个swipwe,用来承载相册。

如图所示,这是两个swiper正在进行滚动动画。
当时在做这个时候,觉得那么多照片正好可以分成两类,一类是成品,一类是原料,让用户可以分类查看。但是我又不想让用户在看到两个相册时,觉得成品和材料就只有一张照片。一想,用swiper正好可以解决这个问题:
让用户看到轮播滚动的图片,每张图片存在时间不长,用户就会想点击放大的图片来延长查看时间,正好落入圈套,进入相册,看到所有图片。
首先是准备了两个view容器,然后在容器中放进swiper,对swiper进行for循环。这整个过程不难,循规蹈矩。但是有个难点,直到项目做完我也没能找到方案:
现在是两个view容器装了两套swiper,如果有更多的swiper,需要更多的view容器,假定数据一次性发过来,怎么样可以循环view的同时,将swiper里面的item也循环?
大概的样子就是:
<view wx:for="{{list1}}">
<swiper>
<swiper-item wx:for="{{item.list}}" wx:for-item="items">
<image src="{{items.src}}" />
<swiper-item>
</swiper>
</view>
数据结构大概是:
data:{
list1:[
{list:[{title:"111",src:""},{title:"222",src:""},{title:"333",src:""},]},
{list:[{title:"444",src:""},{title:"555",src:""},{title:"666",src:""},]},
{list:[{title:"777",src:""},{title:"888",src:""},{title:"999",src:""},]},
{list:[{title:"aaa",src:""},{title:"bbb",src:""},{title:"ccc",src:""},]},
]
}
上面的代码在循环中肯定出现问题,但是我目前没有找到对应的方法解决。
4、总是有报错渲染层网络层出错

这个问题我相信写小程序的应该都遇到过。目前我没找到什么有效解决方案。在社区看到说清除网络缓存。但是在下一次编译时又会出现。如果每次都要清除缓存,好像并不算是个解决问题的方案。
好在这个错误并不影响整体功能,我就
作者:NuLL
来源:juejin.cn/post/7254066710369763388
没有去做任何处理了。












![[舔屏]](http://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/40/pcmoren_tian_org.png)





![[污]](http://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/3c/pcmoren_wu_org.png)

![[坏笑]](http://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/50/pcmoren_huaixiao_org.png)

















